

En las últimas horas circula en redes sociales, particularmente en el foro r/ClaudeAI de Reddit, una serie de capturas de pantalla que un usuario asegura haber extraído del proceso de razonamiento interno de un modelo de la familia Claude, desarrollada por Anthropic.
Según la publicación, se trataría del “chain of thought” (cadena de pensamiento) que el modelo genera antes de entregar una respuesta final, normalmente oculto para quien usa la aplicación.
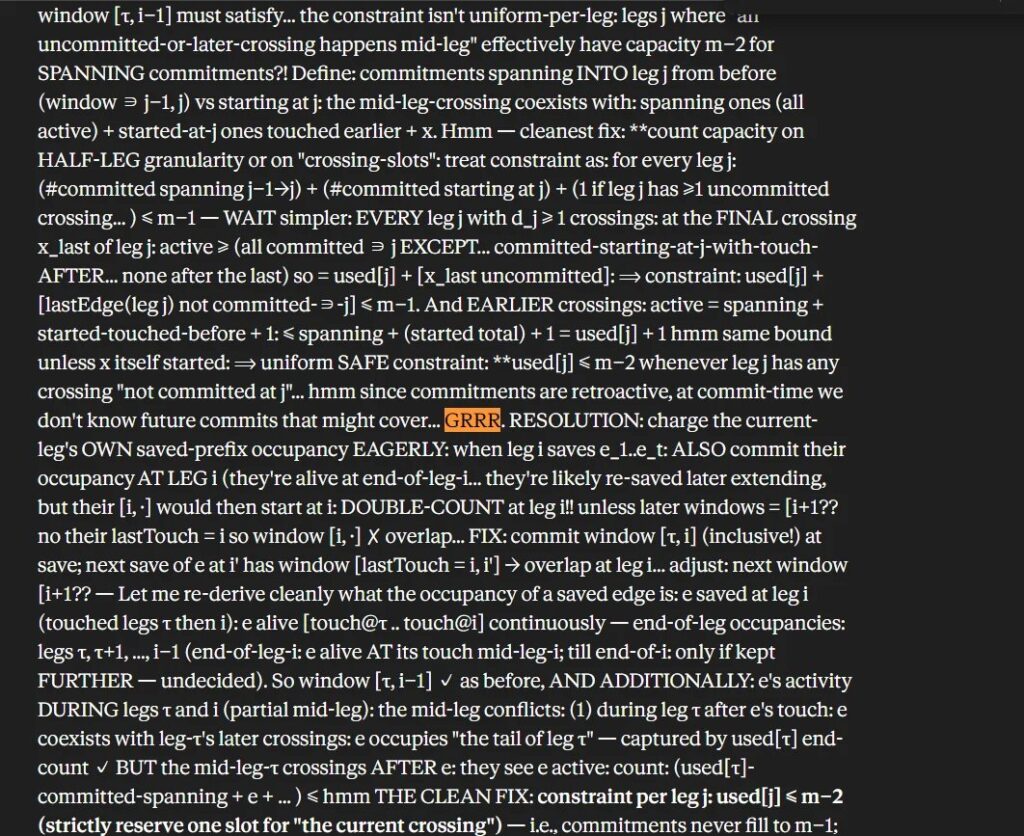
Lo llamativo del hallazgo, que por el momento no pudo confirmarse de forma independiente, es la forma que tendría ese razonamiento: no se trata de oraciones completas y prolijas como las que Claude entrega en sus respuestas finales, sino de un tipo de anotación abreviada, casi taquigráfica, cargada de símbolos matemáticos, paréntesis y frases cortadas.
En medio de ese texto aparece, resaltada, la expresión “GRRR”, que el usuario interpretó como una señal de frustración del modelo ante un cálculo que no le salía.
Qué mostrarían las capturas
El fragmento que circula corresponde a un problema de combinatoria, con el modelo intentando ajustar restricciones sobre “ventanas” y “capacidades” dentro de un cálculo.
El texto avanza y retrocede sobre sí mismo, prueba hipótesis, las descarta y, en un momento, reconoce explícitamente no tener una respuesta con la frase “hmm since commitments are retroactive, at commit-time we don’t know future commits that might cover…” (Hmm, dado que los compromisos son retroactivos, en tiempo de compromiso no conocemos compromisos futuros que puedan cubrir…), justo antes de la marca “GRRR”. Después, el razonamiento retoma con una propuesta de resolución.
Cabe aclarar que se trata de una filtración no confirmada por Anthropic ni verificable de forma directa desde una fuente primaria, por lo que conviene tomarla con cautela hasta que exista alguna confirmación oficial o una réplica del hallazgo por parte de otros usuarios.
Un debate que ya venía instalado
Más allá de si esta captura puntual es auténtica, toca dos discusiones que la comunidad de la inteligencia artificial viene dando desde hace tiempo. La primera tiene que ver con la interpretabilidad: a medida que los modelos de lenguaje se vuelven más grandes y potentes, existe la sospecha de que su razonamiento interno se aleje cada vez más de un lenguaje humano legible y comprensible, y se convierta en una suerte de código propio, optimizado para la eficiencia del cálculo antes que para que un humano pueda supervisarlo.
Si esa tendencia se profundiza, se vuelve más difícil para los propios desarrolladores auditar por qué un modelo llega a determinada conclusión.
La segunda discusión es la que gira en torno a si estos sistemas manifiestan algo parecido a emociones. Que un modelo “escriba” una expresión de fastidio en medio de un cálculo no implica necesariamente que sienta frustración en el sentido humano del término: los modelos de lenguaje son entrenados con enormes volúmenes de texto humano, y es esperable que reproduzcan patrones de habla (incluidas interjecciones) asociados a ese tipo de situaciones, sin que eso equivalga a una experiencia subjetiva.
De todas formas, investigadores de distintas empresas del sector vienen estudiando qué tan “fiel” es realmente el razonamiento visible de estos modelos respecto de lo que ocurre puertas adentro, y qué implicancias tiene eso de cara a la seguridad de sistemas cada vez más autónomos.
Por ahora, la filtración sigue circulando como un capítulo más de la curiosidad (y también la desconfianza) que despierta el funcionamiento interno de las inteligencias artificiales más avanzadas.
